
This post is a continuation from Part 1: Preplanning and Evaluation in a 9 part series. If you want to download the full checklist or slides without all the wordy-word stuff: you can find it in this Github repository. (The checklist has wordy-word stuff. No getting around that.)
Topics covered today:
- Digital Estate
- Data Management
- Data Lineage
- Pilot Project
Digital Estate
Understanding your digital estate at the beginning of your project will help you determine what to assess and migrate down the road. Even if you already think you know all the things you need to migrate, it’s helpful to check how all of the things may be connected. You need to identify your infrastructure, applications, and all the dependencies. You don’t want any surprises! Don’t just rely on old documentation.
Azure Migrate has a Discovery and Assessment tool that can assist in this task, but there are certainly many other ways to acquire this information. You may have other 3rd party tools or internal processes that already gather this information for you. Just make sure that it is UTD. Personally, I really like the free pre-Azure Migrate solution: Microsoft Assessment and Planning Toolkit as it dumps everything in excel sheets that Admins and Management tend to like to see. But the visual display of Migrate (and ALL the additional tools) is pretty fantastic.
Whatever tool you use, from a database perspective, you want to know things like what database systems are in your environment, what version and edition they are on, how many databases may be on an instance, what are the database names, file sizes, statuses, users, configurations, and other various database metadata. You are going to want to know some performance metric results and additional server details. You are going to want to know the various components that are installed on your servers, details about those components, and how they are used. Are you REALLY using those SSRS and SSAS components and if so, how?
Lastly, you want to make sure you know all of your relationships between applications, instances, database objects, and processes. It’s no fun to find out later that you had a database with hard-coded servers in some stored procedures or unknown linked server requirements. Or a SQL job that PBI Report Server created for each data refresh.
The Key Take-Aways here:

1.) Identify the infrastructure : things like servers
2.) Identify what apps do they use – this includes all your SQL server apps!
3.) And identify dependencies they may have: Internally and across servers. Don’t forget to include things like ports/networking
Data Management
Now is the time to find out what documentation you have about your data (and what you need to get). Having this information is essential if you determine you need to move things in parts or if you have overlap in data that might be potentially consolidated. This will help you down the road when we get into some architecture designs with the 5 Rs of rationalization. Our focus here is on having a data dictionary, a business glossary, a data catalog, and classifying your data.

A quick summary of these terms: a data dictionary helps you to understand and trust data in databases better, a business glossary provides a common language for the organization when it comes to business concepts and metrics, a data catalog helps you to find, understand, trust and collaborate on data, and data classification groups your data elements to make it easier to sort, retrieve, and store.
Why are these things important for migration? First off, they are important just from a data governance standpoint. But more than that, knowing this information up front can save you a lot of headaches down the road. You may have business requirements for some of your data to be labeled in a security context. Maybe you are dealing with highly classified government data, health care data, or HR data. Or you may find you have data type mismatches? And data catalogs often review hidden dependencies that you may not have otherwise known.
All is not lost if you don’t have all of this. Azure has some internal tools like Purview to assist with this, and there are plenty of 3rd party tools. If you are like me, you already carry a script toolbox from the lifetime of your career (some of those scripts from 20 years ago still work!) that you can easily use. Apart from the Business Glossary, there are so many free options and scripts out there that this should not be a showstopper for you. For the Business Glossary – you are going to have to go to the source – your subject matter experts (SMEs).
Data Lineage
In addition to the previous items we mentioned for data management, I want to call out data lineage specifically.
Data lineage gives you insight into how your data flows. It helps you understand how your data is connected and the impact of how changes to your data, processes, and structure, affects the flow and quality of your data. KNOW YOUR DATA FLOW. Find out where your data comes from, how it travels, the place(s) it lands, and ultimately, where it else it goes.
There are a lot of tools that will help you with data lineage; with various levels of sophistication. Long gone are the days where you must shift through excel sheets to figure it all out. That’s why graphical tools like Purview are really exciting for me. [Note: from initial insights into Purview costs once it’s past the preview stage – it gets pretty pricey, fast.] This is an image of Azure Purview and I wanted to show how granular it can get at the column level and how it travels through various processes and databases.
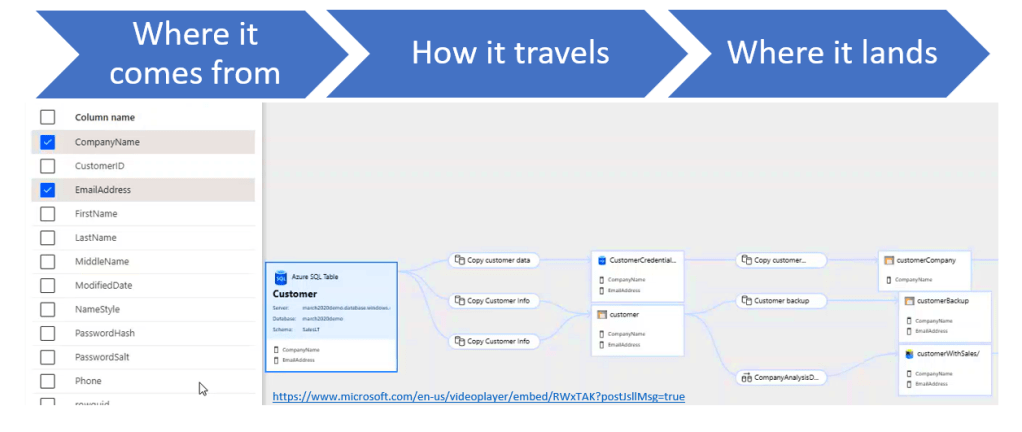
The column level feature is really really nice. It’s not necessary at this stage, but it certainly is helpful to you at the testing and troubleshooting phases. What you really need with your data lineage at this stage – and you can still see it in this graph – is how your dataflows between resources. Because this is a great way to discover things you may not be aware of in your data flow process that you need to pull into your migration plan.
What also can data lineage help with? Reporting considerations. Knowing what can break in a report, if you change at at the source is invaluable. While getting a big picture of what reports, models, applications may be impacted after a migration help circumvent some nasty surprises.
Pilot Project
If you haven’t moved anything to the cloud previously that is related to your infrastructure, then consider having a much smaller pilot project. One that will get you a feel for all of these steps but has a lower risk than your overall project.
What items do you look for in a pilot project?

Maybe you have a database that is only used for a small app that is low risk if the migration doesn’t go as expected. Try to keep your pilot project to applications with just a few dependencies. The goal of this is to a.) help you understand the process and b.) get you a quick win that you can show to stakeholders.
You want one that is low-risk, that is small enough to manage easily, but still large enough with a long enough duration to give you a good understanding of the processes involved. Besides size and duration, the criticality of your project is important. You want to incorporate a visible win that is important to your company that supports making bigger moves.
Finally, ff you’ve already done this previously, then this is when you review what you’ve learned from your previous pilot project. What were gotchas? What went really well? What is easily repeatable and what do you need to get down on paper?
Welp, we’ve come to the end of part 2. Feel free to hit me up with items you think I’ve missed or you want more clarification on. Next week is a much needed break for me, so [probably] no updates from me. Hope everyone has a wonderful Mother’s Day!
From,
DataWorkMom
